A point of view for leaders, professionals, and organizations navigating the future of work
A Workforce at an Inflection Point
We are living through one of the most significant transitions in the history of knowledge work. For most of the modern era, the value of a professional was defined by what they knew — their expertise, their technical skills, their mastery of tools and processes. Knowledge was relatively stable. Skills lasted years. Roles were predictable. Experience accumulated slowly and reliably.
Artificial intelligence has fundamentally changed this landscape.
Today, knowledge evolves faster than organizations can update their training programs. Tools change faster than people can master them. Entire workflows are redesigned in months, not years. And AI systems are increasingly capable of performing tasks that once required specialized human skill.
This is not simply the next wave of automation. Previous technological shifts — from the industrial revolution to the rise of personal computing to the internet — disrupted physical and transactional work. What is happening now is different in kind, not just degree. AI is disrupting knowledge work itself — the analysis, the synthesis, the generation of content, the execution of complex professional tasks.
This shift raises a profound question for leaders, professionals, and organizations:
What should humans focus on when AI can learn faster, execute faster, and update faster?
This article — the first in a two-part series — explores that question through the lens of the half-life of knowledge: the idea that different types of skills and capabilities decay at vastly different rates, and that AI is dramatically compressing the lifespan of some while leaving others largely untouched.
Understanding this distinction is not an academic exercise. It is becoming one of the most practical and urgent questions in workforce strategy.
The Half-Life of Knowledge
The concept of a half-life comes from nuclear physics, where it describes the time it takes for half of a radioactive substance to decay. Borrowed into the domain of knowledge and skills, it describes something equally real: the rate at which what we know becomes obsolete or irrelevant.
For most of the 20th and early 21st century, this half-life was long. A professional could learn a discipline, master a set of tools, and rely on that expertise for a decade or more. Certifications were valid for years. Technical skills had long shelf lives. Experience accumulated slowly and steadily.
In many fields today — technology, analytics, digital operations, and increasingly professional services — that half-life has shrunk dramatically. Consider:
- A programming framework becomes outdated within 18 months.
- A cloud certification loses relevance as new services appear.
- A data-analysis technique becomes obsolete when AI automates it.
- A workflow becomes redundant when a new AI feature collapses ten steps into one.
This does not mean knowledge is unimportant. It means the type of knowledge that matters is changing. And to understand how, we need to look more carefully at what we mean by “knowledge” in the first place.
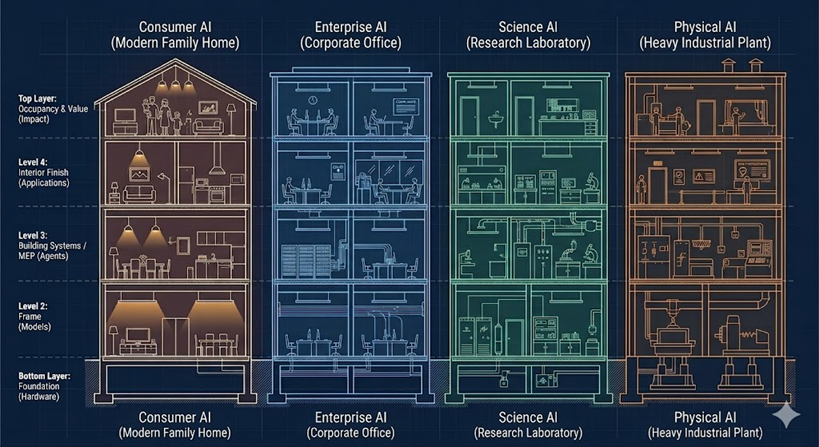
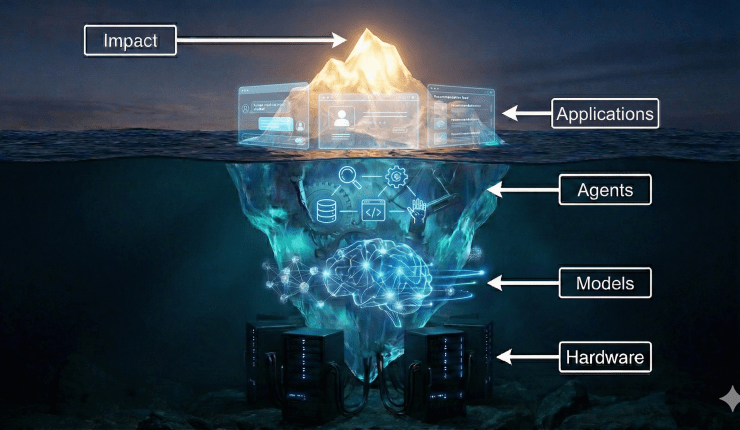
Four Layers — Four Decay Rates
When we say that knowledge is evolving faster than organizations can update, we are really talking about several distinct layers — each with a different half-life, and each affected by AI in a different way.
Diagram 1 — Navigating the AI Workforce Evolution: Four Layers of Knowledge

AI most aggressively accelerates the decay of Layers 1–3. Half-life increases as you move up the layers.
Layer 1 — Tool Knowledge is the most fragile. It is the knowledge of how to use specific software, platforms, or interfaces: how to build a dashboard in Power BI, how to write code in a particular framework, how to navigate a cloud console. This knowledge changes rapidly — tools update, new features replace old workflows, and entire categories of tools can become obsolete.
Layer 2 — Procedural Knowledge describes step-by-step task execution: checklists, workflows, standard operating procedures. It decays because processes evolve, automation replaces manual steps, and AI increasingly collapses multi-step tasks into a single prompt.
Layer 3 — Domain Execution Knowledge is the application of industry-specific methods: writing a financial analysis, creating a marketing funnel, performing supply chain forecasting. AI is absorbing these layers rapidly — not by replacing the profession, but by automating the execution that used to require significant human effort.
Layer 4 — Conceptual Knowledge is the most durable: first principles, mental models, systems thinking, foundational theories. This knowledge remains essential — but critically, the way it is applied changes as AI reshapes work around it.
This taxonomy matters because it reveals a pattern: the higher the layer, the longer the half-life. And AI is most aggressively compressing the bottom three.
How AI Compresses the Half-Life
Non-durable capabilities — the tool-tied, procedural, and execution-heavy skills in Layers 1 through 3 — were already decaying before AI arrived. Tools have always evolved. Processes have always changed. Certifications have always expired. This is not new.
What AI has done is dramatically accelerate that decay. And it does so through five distinct mechanisms.
1. Collapsing multi-step workflows
Tasks that once required hours of expert manual effort — compiling a report, cleaning a dataset, drafting a proposal, generating code scaffolding — can now be completed with a single prompt. The procedural knowledge embedded in those steps does not disappear; it gets absorbed into the model. The human who knew how to execute the ten steps no longer has a differentiated skill.
2. Automating execution at speed
Summaries, analysis, first drafts, code, reports, and visualizations are generated in seconds. The value of being the person who could produce these outputs is declining. The value of being the person who can direct, evaluate, and judgment-check them is rising.
3. Absorbing domain knowledge at scale
Large language models are trained on vast repositories of domain-specific knowledge — financial analysis methodologies, marketing frameworks, legal precedents, engineering standards. This reduces the premium on human memorization and recall of domain execution patterns. The model often knows the framework. The question is whether you know when to apply it, when to challenge it, and what it misses.
4. Updating faster than humans can learn
New features, new models, new capabilities appear weekly. The average organizational training cycle — designed for annual updates and multi-day programs — cannot keep pace. By the time a learning program is designed, piloted, and deployed, the technology it describes has already shifted.
5. Reducing the value of procedural expertise
If a task can be described as a reproducible sequence of steps, AI can likely perform it — often better, always faster. Procedural expertise is, by its nature, describable. And what is describable is, in principle, automatable.
Non-durable skills were already melting ice cubes. AI simply turned up the heat.
The Compounding Loop: AI Accelerating Its Own Acceleration
Here is where the shift becomes more profound — and more disorienting.
AI is not just accelerating work. It is accelerating its own evolution. AI-generated code is being used to train better AI models. AI-assisted data labeling is improving the next generation of systems. AI-generated synthetic data is expanding training sets beyond what human-annotated data alone could provide. AI-driven research is shortening scientific discovery cycles.
This creates a self-reinforcing loop:
AI improves tools → tools accelerate development → development produces better AI → better AI accelerates everything further.
The implication is significant: this is not a linear curve. The half-life of non-durable skills is not shrinking at a steady rate — it is shrinking exponentially. And traditional organizational responses — training cycles, certification programs, skills audits — were designed for a world where change was linear and predictable.
Organizations that respond to an exponential shift with linear tools will find themselves perpetually behind.
Diagram 2 — The Half-Life Curve of Human Capabilities
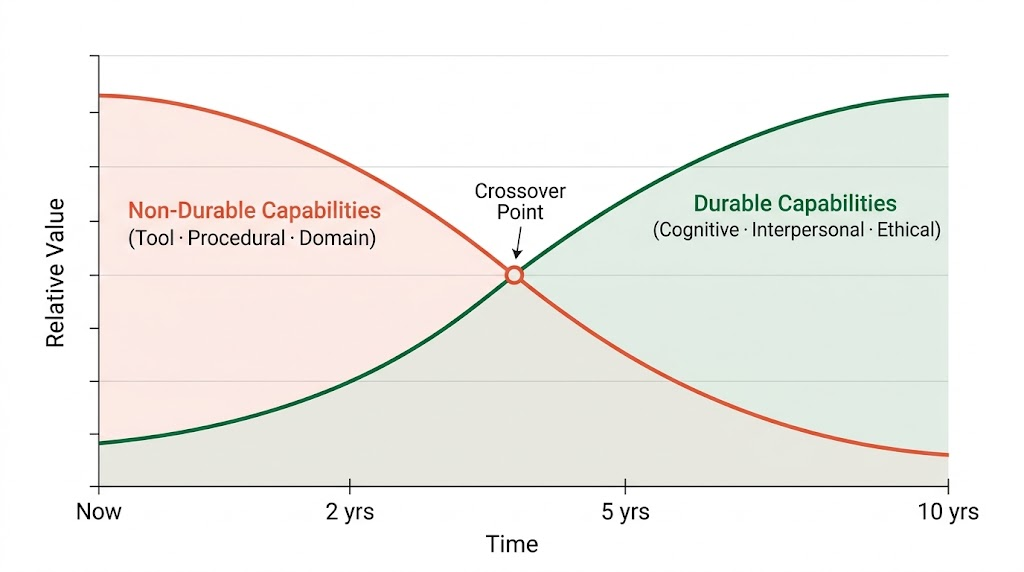
As AI scales, non-durable capabilities lose relative value while durable human capabilities appreciate. The crossover point is not theoretical — in many fields, it is already happening.
As AI becomes more capable, the capabilities it cannot replicate — judgment, empathy, meaning-making, ethical reasoning — become the primary source of human differentiation. The crossover point is not theoretical. In many fields, it is already happening.
Where This Leaves Us
The ice is melting faster than it ever has. The four knowledge layers are decaying at different rates, and AI is not just accelerating the decay — it is accelerating its own acceleration, compressing timelines in ways that traditional L&D cycles were never designed to handle.
That is the diagnosis. But a diagnosis without a response is just anxiety.
The more interesting question — and the one that will determine which professionals and organizations emerge stronger from this shift — is this: if AI is absorbing the execution layers, what exactly do humans bring that AI cannot replicate?
And more practically: what does it actually look like to build an organization — and a career — around capabilities that don’t expire?
Part 2 explores the human edge: the durable capabilities that appreciate as AI scales, and how organizations can build around them.